Repcode.io
A full-stack application to assist software engineers with technical interview preperation via spatial repition learning
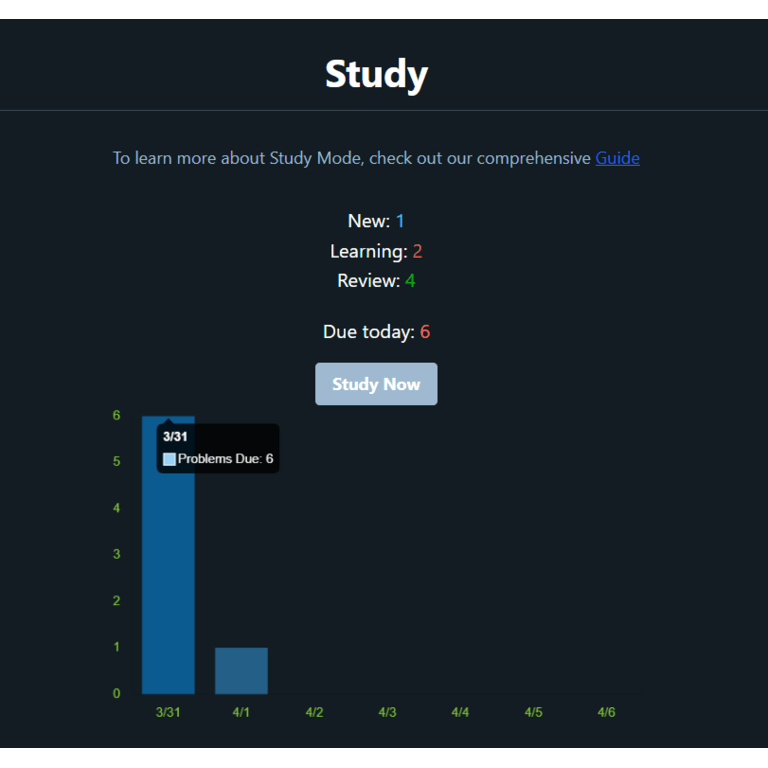
Tech Stack:
Alright, before we begin, I need to come clean: this project wasn't just done in March. Although I worked on it almost every day in March, I actually began development in early January, so I suppose I sort of cheated. But a lot of the major development took place this month so I'm still counting it!
I'm really proud of this project - this is something that I put a lot of effort into, and I really do think it is something many others will find useful. The new technologies I was learning for this month was database-related stuff - so in this case, MySQL, Prisma ORM, and AWS. I was familiar with databases and interacting with them from past projects, but only NoSQL solutions like Firestore. I had never really worked closely with an SQL database before, so this was a great opportunity to learn more about this very important aspect of CS. I'm hosting my MySQL database on AWS. I considered using DigitalOcean, but went with AWS as I think it is more industry standard. But anyway I'm getting ahead of myself, I know you're probably wondering, what exactly is Repcode? So let's start there. Repcode.io is a full-stack application to assist software engineers with technical interview preperation via spatial repition learning.
When I first started preparing for technical interviews, I did what pretty much every aspiring software engineer does: I created a Leetcode account and started doing problems, starting with Array problems marked as Easy. I quickly ran into the first major issue: how can I organize these problems? Where can I store them for quick lookup and retreival later? Leetcode does actually have a built-in My Lists page that lets users create and customize their own problem collections, but there are three major problems with it: first, it is unintuitive. It is tricky to figure out how to add your own custom solutions to problems, and you can't customize the problem at all. Second: you can only add problems from Leetcode to these lists. So if it a problem from any other source you are out of luck. Third: The My Lists page simply offers a way to organize problems, but what about a strategy for practicing them? When you only have 10 or 20 so problems that you are familiar with, the problem solving strategy is simple: just do those problems every day so you remain familiar with those concepts. But what about when you have 50, 100, 500 problems? It is no longer feasible to work through every single one. The SuperMemo 2 spatial repitition style of learning is one solution to this problem: strategically space out when you solve the problems so you only are doing a manageable amount every day. So thus, Repcode.io was born to bridge this gap between organization and learning.
Now, if you're curious about what the different pages of the application do and how exactly you should best use it, or how the spatial repition algorithm works, or anything like that, check out the guide page on the website, as it explains everything in great detail. So I won't be doing that here, instead, I'll be going over the more technical aspects and discussing the new technologies that I used and how they work, and also some other interesting things I learned (as remember the purpose of this website isn't to advertise these projects but rather to explore the new technologies I used to make them). So without further ado let's just jump straight into it by talking about server-side rendering and protecting routes.
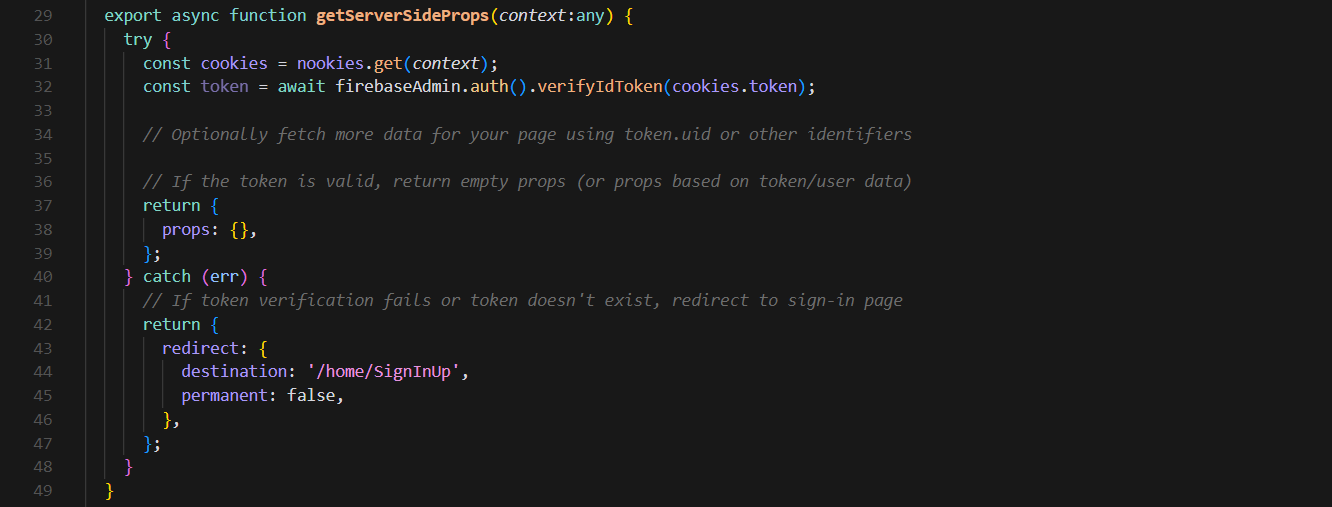
It may not seem like much, but I think this is actually a really clever way to handle protecting pages to make sure only authenticated users can access them. In the above code, getServerSideProps function serves to pre-fetch data on the server side before rendering the page to the client. Specifically, it checks if the user is authenticated by verifying a token stored in cookies (using FireBase auth and the nookies library to handle the cookies). The cookies are set when the user logs in. And based on that, the token is determined. And based on the success of this token, the user will be either redirected somewhere else, or the page they were trying to access will be rendered! Now, you can actually accomplish something similar by using useState to check the auth, and then redirect the user somewhere else if they are not signed in, but the main issue with this approach is that, it is a client-side approach that can be easily circumvented by disabling javascript. Server-side solutions are a lot more secure, and so, for any page that needs to be protected, I just copy/paste this function at the bottom and it works like a charm!
Alright, now let's move on to talking specifically about the new technologies I used: Prisma, MySQL, and how the two interact (and also a little about how SQL databases work). Prisma is really cool. I actually find it really simple to set up and configure, and it just makes sense in my head how everything works once it's all set up. To get started with Prisma (assuming you aready have a database created and being hosted somewhere), after you install it the first step is to run the command 'npx prisma init' to create a file called schema.prisma:
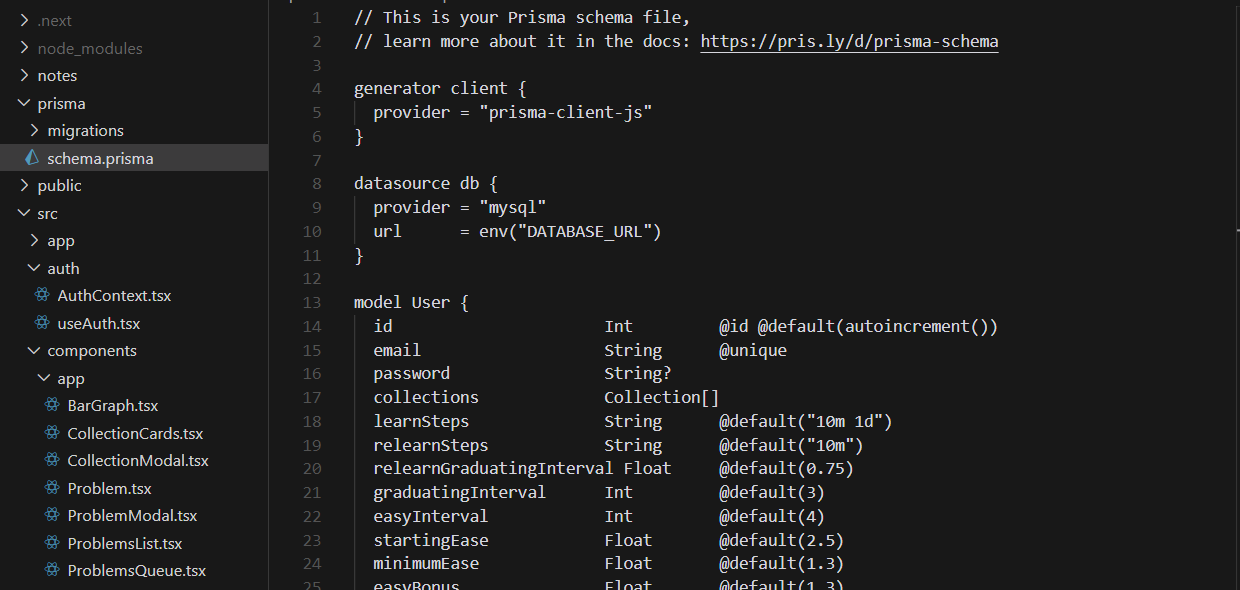
This is the heart of how Prisma interacts with your database. For the provider, write the name of the database you are using (so in my case this is MySQL), and then for url, input the url of the database to establish a connection (for AWS hosting you can find this on the dashboard). So now that your code base and database are connected, you can actually start creating the tables and columns. In the above image you can see part of a table called Users that I created. Once you've created all your tables in the prisma file, simply run 'npx prisma generate' to actually build these tables in the database. And that's it! The really powerful part of Prisma is that you can make as many changes to these tables as you want, and then simply run this generate command to apply them to the database. Multiple times throughout this project, I made several changes to the schema, such as adding/removing columns and changing their types, and each time I was able to successfully and easily migrate these changes to the actual database. One other thing I want to mention is that to make sure everything works properly and the database contains what I want it to contain, I use an application called MySQL Workbench. It lets me view and query any database I have the info for locally. Anytime I made changes to the database I would always double check in the application to make sure they actually applied. Below is an example of what the interface looks like.
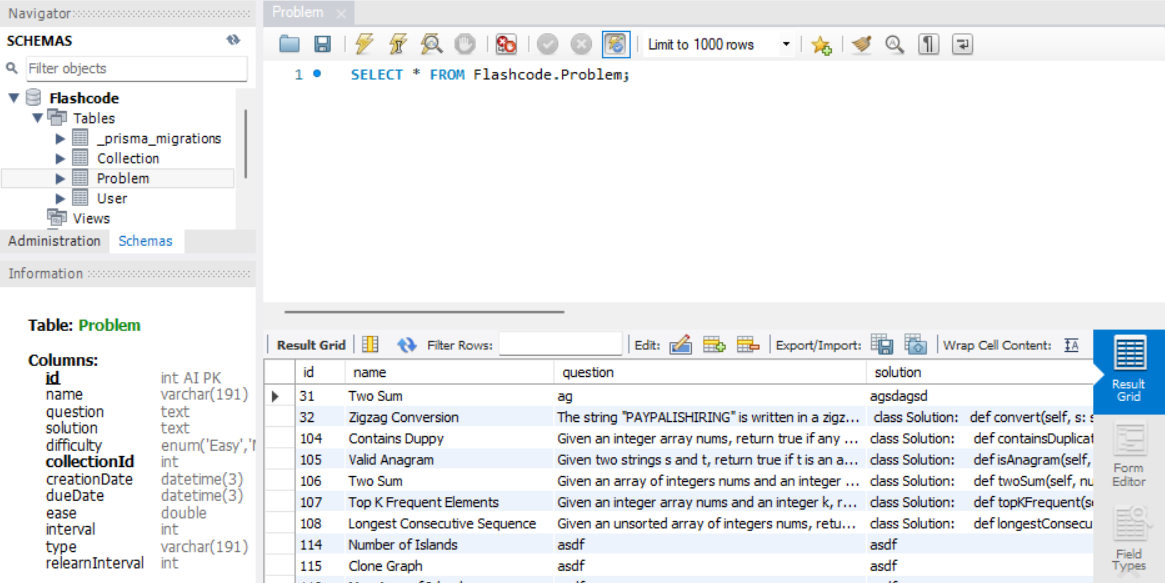
Oh and another cool thing about Prisma is that, if you already have an existing database schema and want to import it (or 'pull' from it) to create the schema.prisma file, you can do so by running the command 'prisma db pull'. This will create the equivalent prisma schema given your existing database schema. So as you can hopefully see by now, Prisma is a very versatile and powerful tool.
Okay, so now that you have your database connection and schema configured, how do you actually query stuff? Well, this part looks different depending on what enviornment you're using. Since this repcode.io uses React and Next.js, the examples will showcase how to query the database using Prisma in that enviornment specifically. But, even though the process may look different in a different tech stack, the general idea is the same. So let's take a look at a specific example in our project that queries the database to understand how it works: when the user logs in, they are directed to a page that displays all the collections that they have created. So, how do we get all the collections in the database that are associated with the user? Well it starts with creating an API endpoint for this query in this directory: pages/api.
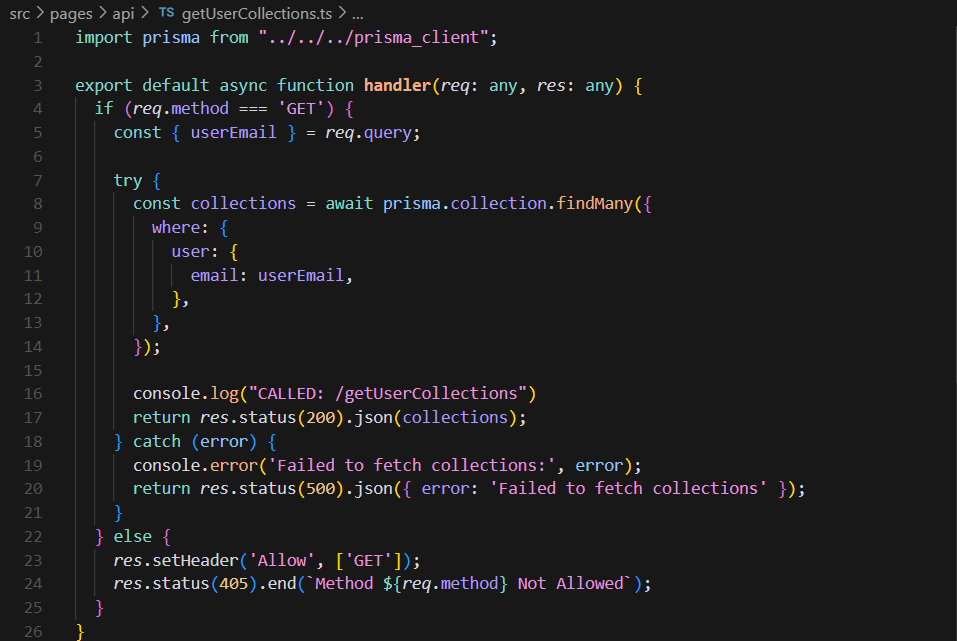
This endpoint is what actually uses the Prisma client to communicate with the database, i.e, send a request given something (the user email) to retrieve something (all the collections associated with that user email). So for every database query I want to do in the application (fetching collections, creating problems, deleting users, etc), there is an endpoint associated with it (getCollections.ts, createProblem.ts, deleteUser.ts, etc). It is this endpoint that actually queries the database, and then throughout the application whenever I want to query the database I am actually sending a request to corresponding endpoint first, then using the returned data:
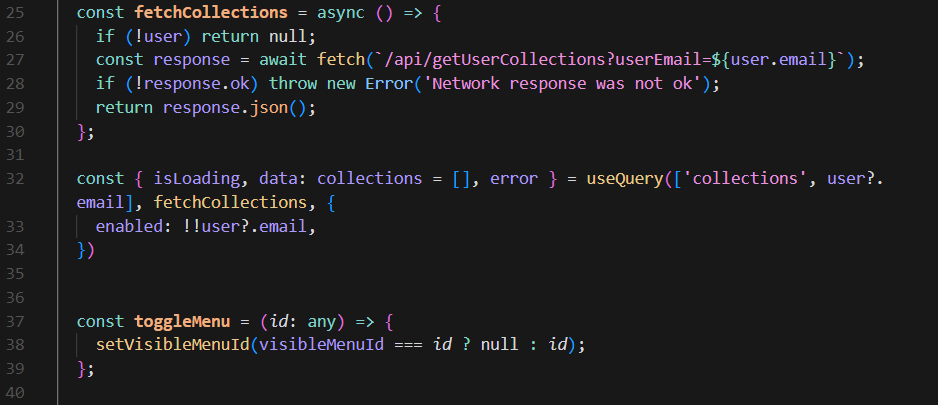
So here I'm using FireBase to get the user's email, then React Query to use that email to send a request to the above API to get all the collections associated with the user. Then we can access all these collections by simply using the word 'collections'. So in the return statement, I map over collections (collection as collections) and display collection.title and collection.image to render each of the collection cards on the home page. As I mentioned earlier this is specific to a React/Next.js tech stack, but in a different tech stack this process of connecting to the database, querying it, and getting the reponse back remains the same from a high level:
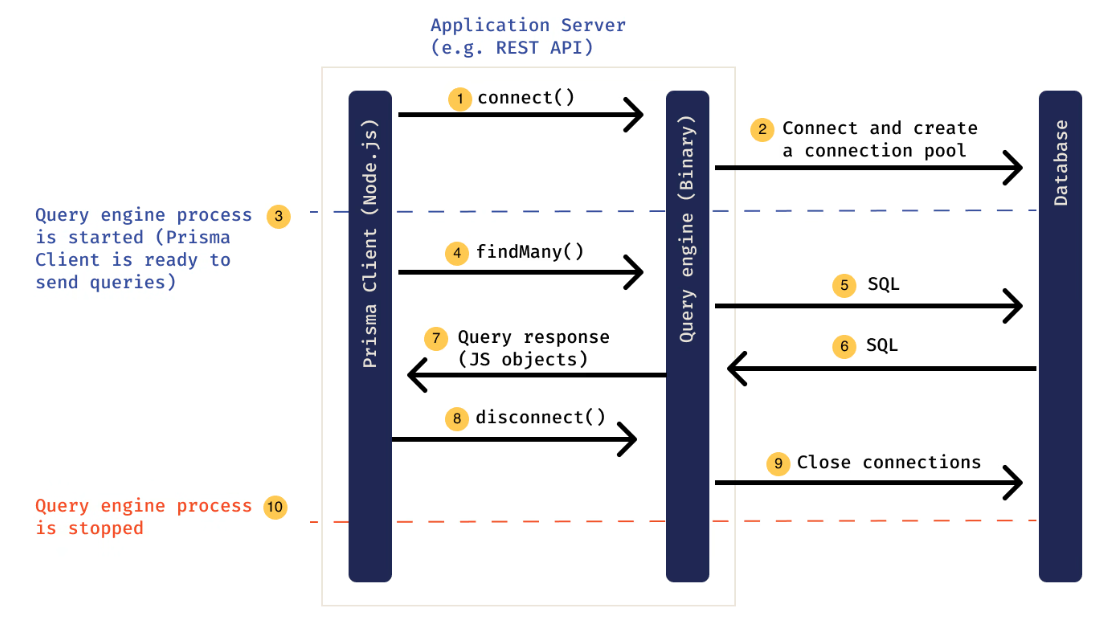
The last thing I would like to touch on is the actual concept of a database, specifically a relational database like MySQL. As you probably know, database serves as the backbone for storing and managing data in a structured format within full-stack development. In the context of full-stack development, it plays a crucial role in the backend, allowing for the efficient retrieval, insertion, and manipulation of data through SQL (Structured Query Language). This data can then be used by the front end to dynamically display content to users (for example, in Repcode.io, collections details are stored in the database, then fetched and their contents are displayed in an intuitive UI). Now because Prisma is an ORM (Object-Relational Mapping), it simplifies the interaction between the Next.js application and databases like MySQL by abstracting the complexities of direct SQL queries. This means we can work with the database using TypeScript instead of having to write the actual SQL code from scratch.
So to recap, as the image above shows: SQL (Structured Query Language) is the standard programming language used to manage and manipulate relational database management systems (RDBMS). These systems store data in tables linked by relationships, enabling complex data organization and retrieval. SQL allows for querying, updating, and managing the data within these databases. RDBMS like MySQL, PostgreSQL, and SQLite support SQL. And Prisma (An Object-relational Mapping) helps us manage and interact with these databases with regular code in a clean and intuitive way. I really like backend database-related stuff, I think, as of right now, it's the aspect of CS I enjoy the most and what I think I'm best at, when it comes to setting up the DB and solving problems related to it. If you read this far you're a legend - and also as I mentioned earlier Repcode.io is going to be actively maintained by me for the foreseeable future, and if you want to help out with it please contact me! I would love the extra help :)
Well, that's about it for now. See ya in April!


