CustomNPC's Script Generator
A tool to generate scripts for the Minecraft mod CustomNPCs
Tech Stack:
This project was an interesting one. AI and machine learning has always been fascinating to me, and it's becoming more and more relevant and intertwined with our daily lives everyday. So I thought this month would be a great opportunity to learn how it works. I wanted to make something useful though: I didn't want to just completely follow a tutorial to build something that's already been built 100 times before just to learn (although there's nothing wrong with this of course), but to keep myself engaged I wanted to use this as an opportunity to actually solve a problem. And I knew exactly what problem I wanted to solve: making the process of creating scripts for the Minecraft mod CustomNPC's more accessible and beginner-friendly.
Alright, now I know what you're probably thinking: "Seriously? Minecraft? You made a script for... Mincraft? What does that even mean?" Well good question, allow me to explain. CustomNPCs is a Minecraft mod with over 20 million downloads that completely amps up what's possible in the game by pushing the engine to its absolute limits. Essentially, what the mod does is add the scripting engine Nashorn to the game, along with a prepackaged, custom-built API based off the game's actual source code, and roughly 3 main "items": Scripted Block, Scripted Entity & Scripted Item. Players can add their own EMCAScript code to these "items" to create... well, anything! Do you want to create an entity that can shoot fireballs and lasers at anything in sight? Program one! What about an item that dynamically changes its texture depending on the time of day and health of the player? You can make a script for this, too! What about a casino with real games and accurate odds, is this possible? Yup! In fact, all three of the aforementioned scripts are real scripts that I've actually made myself (the casino one was meant to act as a visual to teach people why gambling is bad and never worth it). The bottom line is, CNPCs essentially transforms Minecraft into a game engine, and quite a powerful one at that. Alright now, what does one of these scripts actually look like? Well, let's take a look:
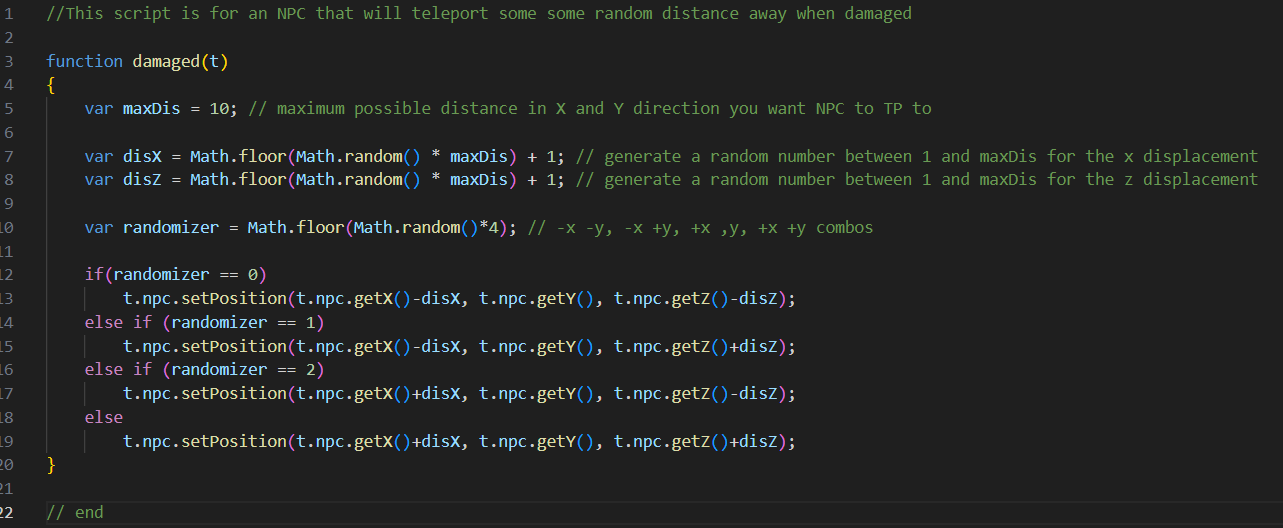
If you're familiar at all with coding, you can probably discern what the above script does without needing to even read the comments. It's pretty simple: when the entity the script is in takes damage, it will teleport to a random spot a short distance away (similar to how the Enderman entity works). Now you might have noticed the use of functions like 'setPositon()' and 'getX()' that don't seem to be defined anywhere: that's because, these methods are part of the CNPC API, and their definitions are abstracted. Here's an example of what this looks like on the API documentation:
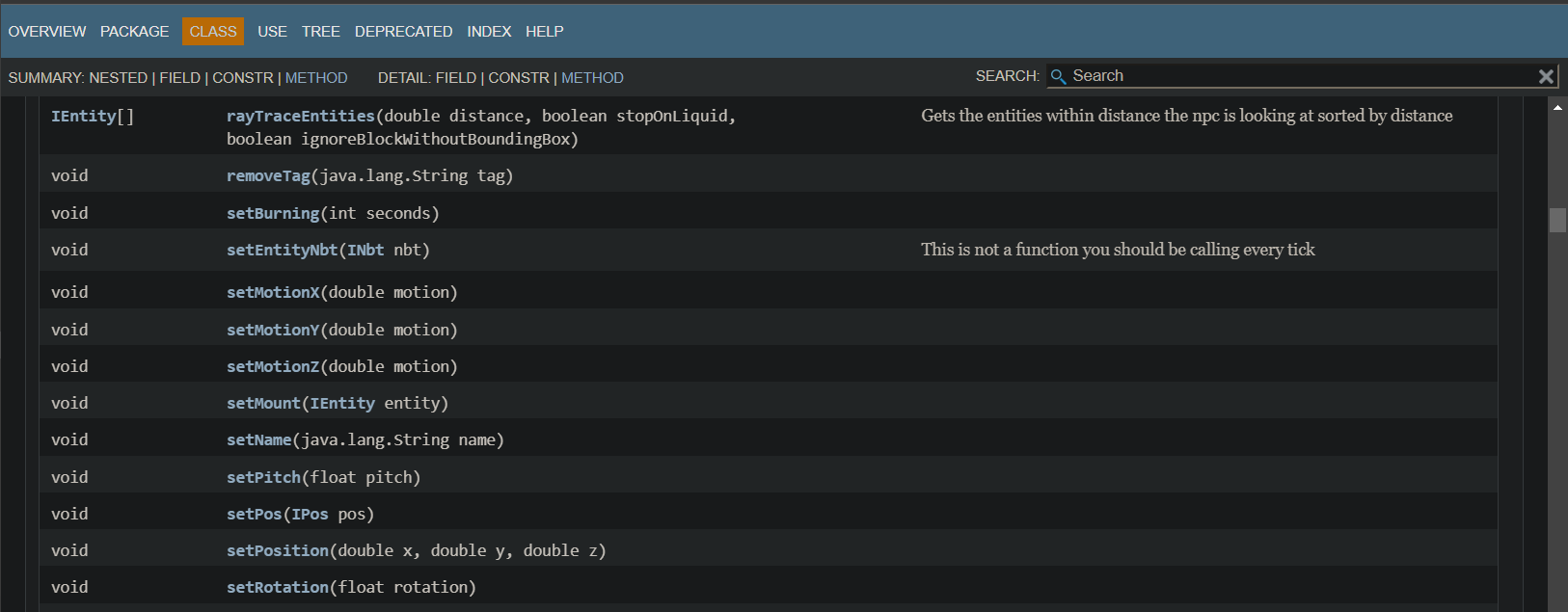
As you can see, there's a list of these predefined methods (this list is for methods that can be used on the interface IEntity), and they can be implemented out-of-the-box. Hopefully, by now you've spotted a major problem with this mod in general: it is not accessible at all for those with little to no programming experience. Imagine you're an 11 year old who wants to make a cool custom dragon entity in Minecraft, but then you take a look at the above example script and API docs (and what I showed is just a simple example) and realize you can't make heads or tails of it. Well, that's the reality for hundreds of thousands of people who want to make cool things with this mod but simply don't have the time or resources to learn programming. And since since the mod relies heavily on the custom API methods, you can't just ask ChatGPT for help since it isn't trained on the API... until now! That's where this project comes in!
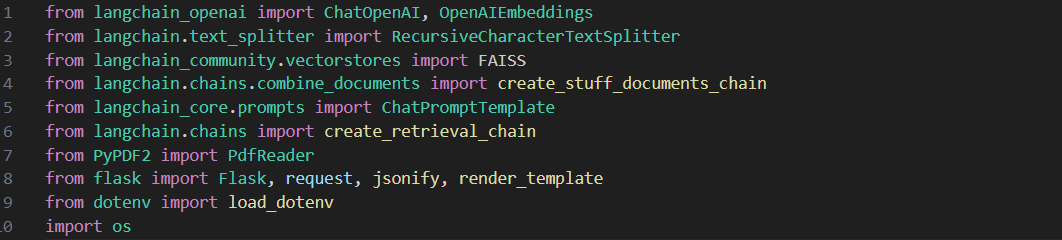
This project is essentially an AI chatbot that is trained exlusively on both the CNPC API and also hundreds of example scripts. The goal was to be able to ask for a beginner to intermediate level script in plain English, and have the AI generate a fully functional one based on your description and requirements (more on the results later). It was built in Python, and I'm using OpenAI for their GPT-4 model and for embeddings, and LangChain for everything else (text splitting, retrieval chains, semantic/similarity search, etc. pretty much all the heavy NLP stuff).
So, how exactly does it work? Well, from a high level, what we're doing is implementing something called a 'retrieval chain', which fetches data from a separate 'database' so to speak and passes that into the prompt template as context for the AI to use to generate a response. The first step was to create the actual knowledge base that the AI would draw from to answer questions. I created a simple PDF document with hundreds of example scripts, with comments detailing what they did, along with most (but not all) of the API's classes and corresonding methods and a description of what they do. You can't just take the PDF and copy/paste its contents into ChatGPT as is, because it greatly exceeds the context window. That's another benefit of this program: by being able to customize the data retrieval and similarity search processes, you can greatly increase the amount of context you can feed to the AI, increasing the accuracy.
The next step involves extracting the text from the PDF (using a python package called PDFReader), wrapping that text into a predefined Document object, and then splitting that text into chunks of a predefined size. We also initialize OpenAI's embeddings model, to be used later.
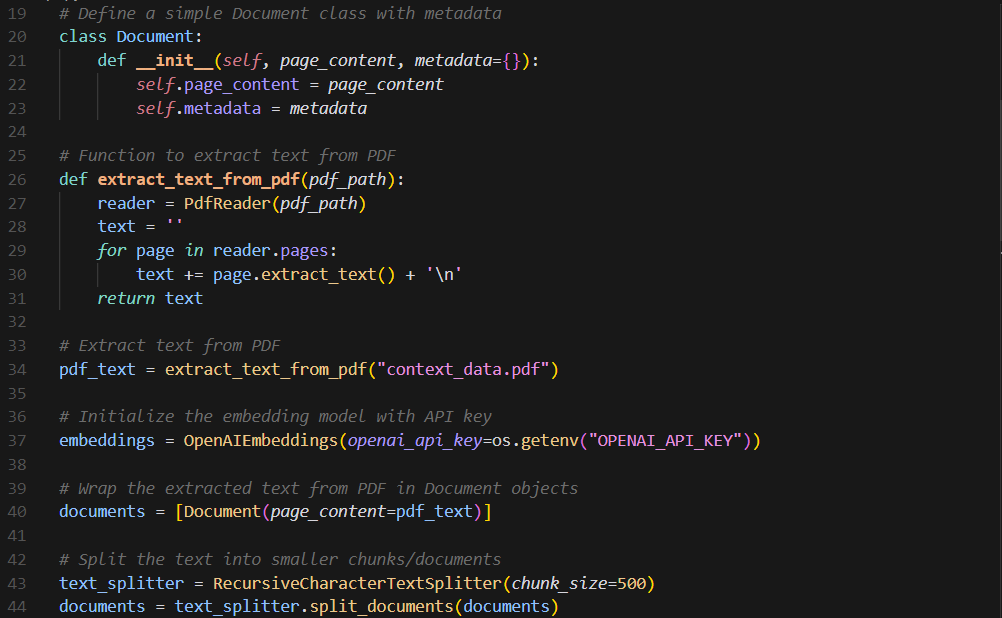
One interesting thing to note is that we are wrapping the extracted text from the PDF in a Document class and then splitting it, instead of splitting it directly. There are several reasons for this: it's more organized, as the Document object contains not only the text but also associated metadata, it's more flexible, as we can easily add more methods to the Document object as needed, and most importantly I was getting an error when I tried to split the text directly and it went away when I used the Document object, so I kept it. You may be wondering why text splitting is even necessary at all, and there are actual several key reasons why this is necessary. Essentially, by dividing a large text into smaller pieces, tasks can be parallelized, meaning multiple chunks can be processed simultaneously, leading to faster overall processing times. This is largely dependent on the Chunk Size (the number of text units each piece of split text should contain): larger chunk sizes mean more context but slower performance, while smaller chunk sizes are often faster but as the cost of losing context. For the size of my PDF, I found that a chunk size of 500 yielded the most accurate results, but feel free to play around with this value on your own.
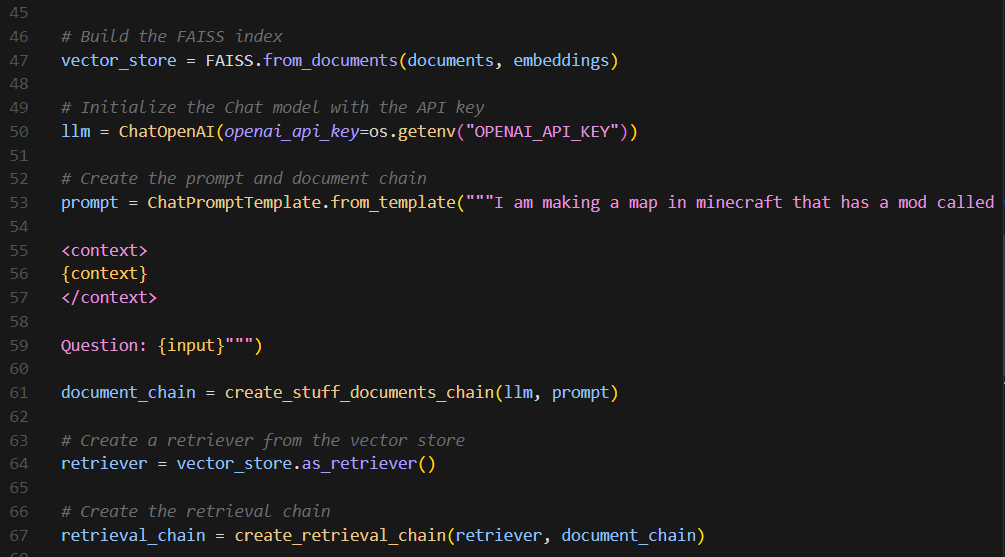
Alright, now we move on to the fun part. Once we have our extracted and split text, the next steps are to create embeddings for the document using FAISS (FaceBook AI Similarity Search), initialize the LLM and provide it with a template prompt (creating the document chain), and finally create the retrieval chain to tie everything together.
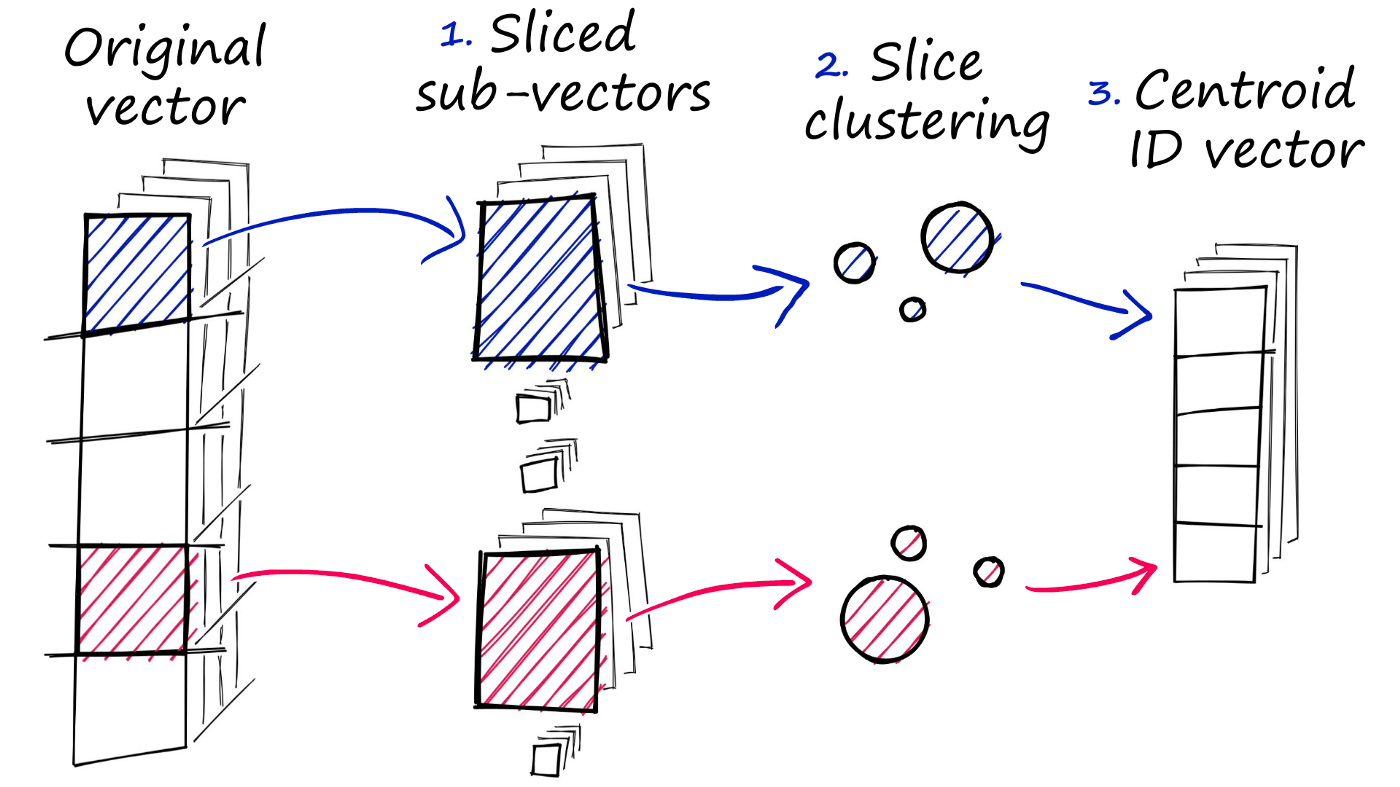
First let's talk about FAISS and the embeddings creation process. Essentailly, FAISS allows for efficient similarity search by creating an index of numerical representations (embeddings) for the documents (in this case, chunks of text from the PDF). Each document is converted into a dense vector using the embeddings provided, which allows us to perform fast and efficient searches to find documents that are similar to a given query. If you want to get technical: when performing a search, FAISS takes a query vector and compares it against the indexed vectors to find the nearest neighbors. It divides each high-dimensional vector into smaller segments or "subvectors." It also perform clustering on large datasets, which is the process of grouping vectors into clusters such that vectors in the same cluster are more similar to each other than to those in other clusters. Below is a diagram that illustrates the process, but if you don't understand it fully (I certainly don't) don't worry, the great part about FAISS and LangChain is that these processes are abstracted for you so can use them effectively without needing to know how exactly they work.
After creating the embeddings, we now initialize the LLM (we are using GPT-4, the most advanced model at the time of writing this) and provide it with a template prompt to define how the chat model should structure its responses. I don't actually think the template prompt step is totally necessary, but more context certainly doesn't hurt, so the templated prompt I initialized it with just gives it more context about CNPC, the API methods, and how the user is likely going to structure their query. The 'create_stuff_documents_chain(llm, prompt)' function combines the LLM with the prompt template, thus creating the document chain.
Finally, we create the retrieval chain. First we create the retriever object, which is what takes a query, finds the most relevant documents in the FAISS index we made earlier, and returns them. We then use this retriever object together with the document chain to create the retrieval chain, which allows the chatbot to take a user's question, use the retriever to find relevant documents, and then use the document chain to generate a response that incorporates this information, tying everything togther neatly. And... that's it! You've succesfully created an AI chatbot with a custom knowledge base, congratulations! The rest of the code is just setting up the Flask enviornment and making the chat box UI. Below is a diagram, taken from the LangChain website, showing what the whole process looks like:
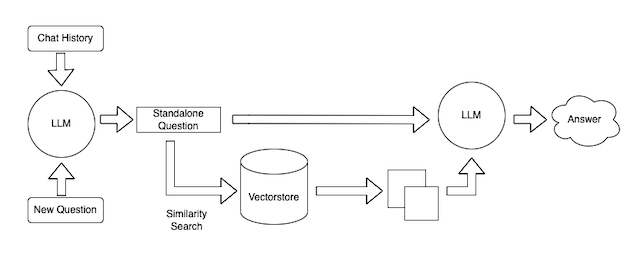
Shoutout to the LangChain docs by the way, extremely detailed and concise, it was an invaluable resource to me in the creation of this project. The only thing is, I was not able to incorporate chat history into this project, simply because I ran out of time. It's not that complicated actually, we just have to make it so that the retrieval chain should now not just work on the most recent input, but rather take the whole history into account, but it's February 29th so it's time I submit this project and move on (leap year came in clutch).
The last thing I want to touch upon are the results: does it all work the way I want it to? Yes!... well, sort of. My initial goal was to have the chatbot be able to generate beginner to intermediate level scripts, and through testing, I've found that it is really good at generating never-before-seen beginner-level scripts, but starts to break down once intermediate/advanced level topics come into play (like threading). The cool thing is, I believe this is simply an issue of not having enough example scripts in the PDF, so I'm hoping that, the more I update it to include more difficult scripts, the more accurate the chatbot will become! Although I'm no longer going to work on this project for now since I've more or less completed what I set out to do, I am by no means finished with it. I hope to one day host it on a website where users can input their own API key and use it to their hearts content, both for generating and also debugging CNPC scripts. If you've made it this far, thanks so much for reading and I hope you learned something today ♥
Well, that's about it for now. See ya in March!


